Пакфайлы
Это глава объясняет подробнее, вниз до самых битов, какой формат записи у пакфайлов и у индекса пакфайла.
Файл с индексом пакфайла
Первое, у нас есть пакфайл индекса, который в основе просто группа закладок в пакфайле.
Существуют две версии индекс пакфайла - версия один, которая по умолчанию для Git старше версии 1.6 и версия два которая по умолчанию начиная для Git с версии 1.6, но может быть прочитана Git вплоть до версии 1.5.2, и даже была портирована глубже до версии 1.4.4.5 если вы до сих пор работаете с версией из серии 1.4..
Версия два также включает CRC контрольную сумму каждого объекта и упакованные данные могут быть скопированы прямо из пакета в пакет во время операции переупакования без того чтобы поврежденные данные оказались незамеченными. Индексы в версии 2 могут также обрабатывать пакфайлы размером более 4Gb.
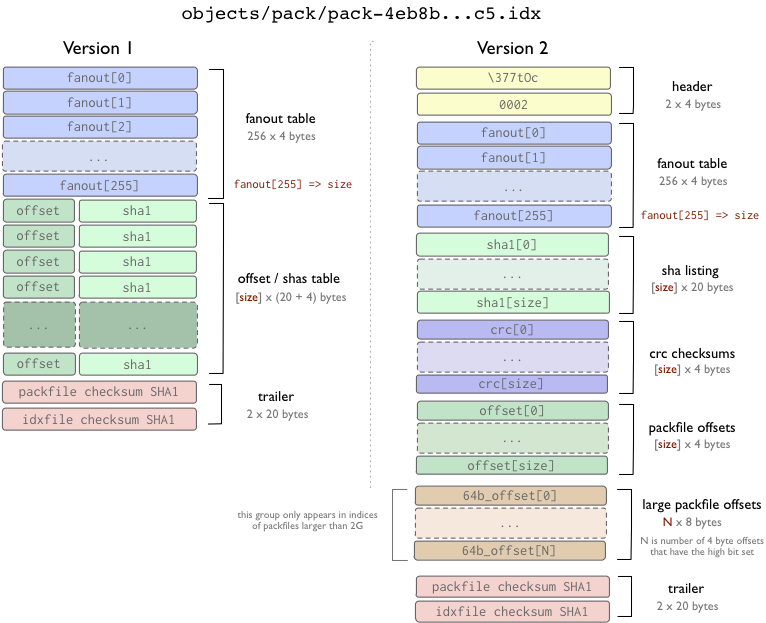
В обоих форматах, таблица ветвления это просто способ быстро найти смещение определенного sha внутри индекс файла. Таблицы offset/sha1[] сортируются по sha[] значениям (это для того чтобы позволить бинарный поиск по этой таблице), и таблица fanout[] указывает на таблицу offset/sha1[] определенном способом (таким образом что часть последней таблицы которая охватывает все хэши которые начинаются с данного байта могут быть найдены, чтобы избежать 8 итераций бинарного поиска).
В версии 1, смещения и sha в одном пространстве, тогда как в версии 2, существуют раздельные таблицы для sha, crc и смещений. В конце обоих файлов проверочная сумма sha значений для обоих индекс и пак файлов на который он ссылается.
Обратите внимание, индексы пакфайлов не обязательно выделяют объекты из пакфайла, они просто использованы чтобы быстро получить отдельные объекты из пакета. Формат пакфайла используется в программах upload-pack и receieve-pack (push и fetch протокол), чтобы передавать объекты и индекс в этих случаях не используется, так как он может быть собран после, фактически при сканировании пакфайла.
Формат пакфайла
Пакфайл сам по себе очень простой формат. Существует заголовок, группа упакованных объектов (каждый со своим заголовоком и телом) и затем в конце контрольная сумма. Первые четыре байта это строка 'PACK', которая гарантирует что вы правильно определили начало пакфайла. Затем идет еще 4 байта версии пакфайла и затем 4 байта количество записей в этом файле. В Ruby, вы могли бы прочитать данные заголовока след.образом:
def read_pack_header sig = @session.recv(4) ver = @session.recv(4).unpack("N")[0] entries = @session.recv(4).unpack("N")[0] [sig, ver, entries] end
После этого, вы получаете группу упакованных объектов, в порядке их SHA значения, каждый из которых состоит из заголовка объекта и содержимого объекта. В конце пакфайла 20 байтовая сумма SHA1 всех sha значений (в отсортированном порядке) в этом пакфайле.
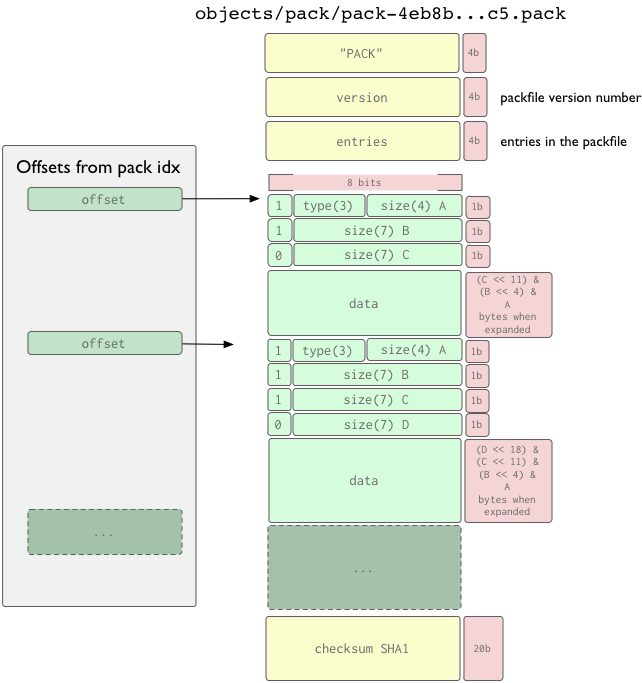
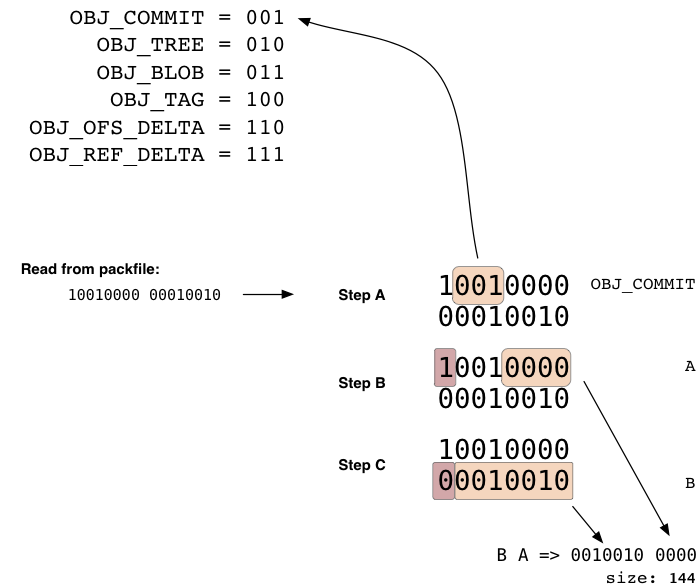
Заголовок объекта это группа из одного или более 1 байта (8 битов) кусков которые определяют тип объекта и последующие данные, и размер данных после распаковки. Каждый байт в действительности 7 битов данных, первый бит используется чтобы объявить что кусок с первым битом использованным чтобы определить если это последний кусок или что данные не начинаются до него. Если первый бит 1, вы прочитаете другой байт, иначе далее идут данные. Первые 3 бита в первом байте определяют тип данных, в соотвествии с таблицей ниже.
(В данный момент, 8 значений которые могут выразить 3 бита (0-7), 0 (000)неопределен а 5 (101) неиспользован.
Здесь мы можем увидеть пример заголовка из двух байтов, где первый определяет что следом идущие данные это коммит, и остаток первого и последние 7 битов второго определяют то что данные займут 144 байта после распаковки.
Это важно понять что размер определенных в заголовке данных это не размер который в действительно последует после, а размер данных после того как они будут извлечены (распакованы). Поэтому смещение в индексе пакфайла так полезно, иначе вы должны распаковать каждый объект чтобы определить когда начнется следующий заголовок.
Часто то что является данными это просто zlib поток для объектов типа non-delta; для представления двух delta объектов, порция данных содержит нечто что идентифицирует от какого базового объекта это дельта представление зависит, и дельта накладывается на базовый объект чтобы восстановить объект. ref-delta использует 20-байтный хэш базового объекта в начале данных, в то время как ofs-delta хранит смещение в пределах того же пакфайла чтобы идентифицировать базовый объект. В других случаях, реализатор должен следовать двум важным ограничениям:
дельта представление должно быть основано на некотором другом объекте того
же пакфайла;базовый объект должен быть того же нижележащего типа (блоб, дерево, коммит или таг);
Примечания: Дельта кодирование алгоритм сжатия основанный на разнице предыдущего и последующих значений.

